

A plant manager at an automotive parts supplier receives a call every operational leader dreads—line 4 has experienced unplanned downtime. The root cause team assembled the following morning. They pull information from MES systems, ERP batch records, maintenance logs, and legacy spreadsheets circulated across teams. Two days later, they identified the core issue: a temperature variance in an upstream process that the sensor detected but was not surfaced in operational workflows. The data existed, but it was distributed across six disparate systems.
This is not a technology problem. It is an architectural failure.
Poor data architecture restricts efficient data utilization, and it is a persistent challenge even in the most advanced US manufacturing sector. A data lakehouse addresses this bottleneck by enabling the unification of factory, supply chain, and operational data. It eliminates data silos and closes the gap between data availability and execution.
As a result, manufacturers are increasingly adopting data lakehouse strategies to leverage data for real-time operational efficiency.
What is a Data Lakehouse in Manufacturing and How Does It Bridge the Architectural Gap?
Most manufacturers operate without unified data access and end-to-end visibility. Every department and shift produces operational data, including production orders, quality reports, and maintenance logs, stored across diverse and disconnected systems. Yet insight gaps occur due to the absence of information sharing between the OT and IT systems.
Industry estimates indicate that over 83% of manufacturers face delays in identifying the root causes of downtime due to fragmented data environments.
A manufacturing data lakehouse bridges this architectural gap by integrating OT and IT data on a unified platform, including
- Industrial IoT and sensor data
- MES and production systems
- ERP and supply chain platforms
- Quality and maintenance records
This unified structure enables both operational teams and AI systems to make data-driven decisions in real-time.
- Proactive decision-making and problem evaluation
- Reduced response times from days to minutes
- Enhanced inter-departmental alignment through a shared data context across all functions
At the same time, it serves as the foundation for AI-powered operations by enabling:
- Consistent access to high-quality datasets
- Accessibility of both historical and real-time signals
- Contextual intelligence across IT and OT systems
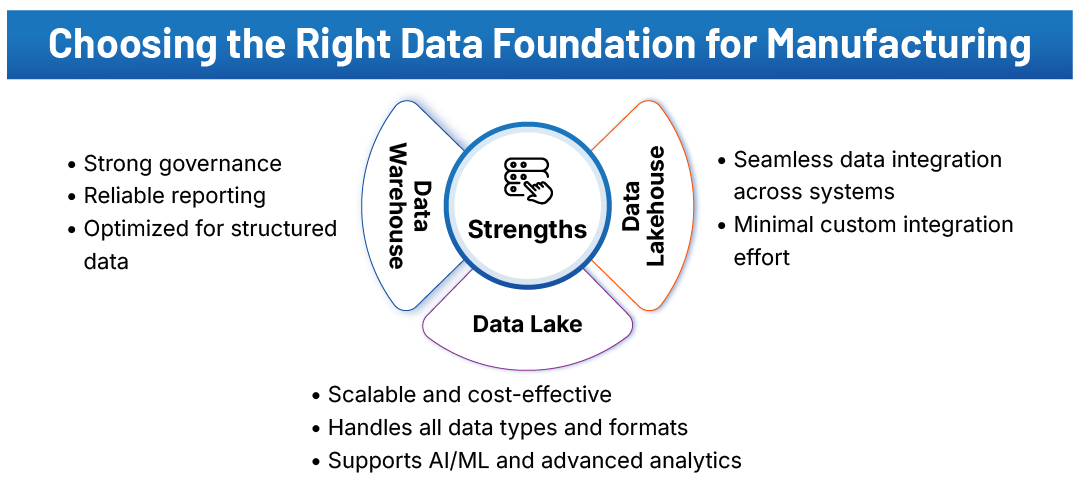
The Build Decision: Warehouse, Lake, or Lakehouse?
For manufacturers operating at scale, choosing the data platform is essential for alignment with business and operational requirements.
Conventional data warehouses are optimized for managing structured business data, governance, and reporting. However, limitations arise when integrating with high-volume, diverse data streams found in modern factories.
Data lakes provide scalable, cost-effective storage for large volumes of data of all types and formats. Data science and AI workloads leverage this data for tasks such as model training and delivering advanced analytics insights. However, this data often lacks consistency and governance.
A data lakehouse offers both the scalability of data lakes and the governance and reliability of data warehouses, offering a unified manufacturing data platform that supports structured and unstructured data. This approach makes it better suited for complex, multi-source manufacturing environments.
The platform acts as an industrial data integration platform that creates seamless data integration across shop floor systems and enterprise platforms without extensive custom integration efforts.
A 2025 industry report finds that the data lakehouse market is expected to grow significantly from USD 14.2 billion in 2025 to USD 105.9 billion in 2034. This shows that more manufacturers are actively implementing data lakehouse strategies.
How Data Lakehouse Helps Manufacturing Analytics?
-
Cross-Facility Visibility: Large companies operate multiple facilities simultaneously, each with its own method of tracking and reporting equipment effectiveness (OEE). Calculations vary based on exclusions, benchmarks, and reporting cycles.
A scalable manufacturing data platform built on a data lakehouse architecture streamlines this process by centralizing production data from multiple systems. This enables dashboards that update continuously, providing real-time visibility into OEE and other essential performance metrics.
The unified data platform accelerates insight-driven decision-making across the organization. -
Traceability Without Forensics: During regulatory audits or when addressing customer concerns, manufacturers must sift through multiple data sources, such as supplier lots, process conditions, inspection results, and shipment records, to establish product traceability.
This process demands inter-departmental collaboration and information consolidation. With an enterprise data lakehouse, end-to-end data lineage is embedded by design. This allows manufacturers to trace processes and products within minutes through a single query, improving audit response times and reducing compliance overhead. -
Machine Learning at Scale: Predictive maintenance pilots often work on a small scale but fail at an enterprise level due to incompatible data formats and integration challenges.
An industrial IoT-enabled lakehouse architecture addresses this by ingesting and standardizing sensor data from multiple sources, combining both historical and live data on a unified platform.
This allows teams to shift from “Can we build models?” to “Which models deliver measurable ROI?”
This approach enables manufacturers to scale AI initiatives into enterprise-wide production operations, improving process efficiency and asset reliability.
A Data Lakehouse Implementation Strategy
Proper implementation of data lakehouse architecture can convert data into valuable business intelligence. It empowers businesses with operational agility and scalability while ensuring cost optimization.
However, certain strategic measures are necessary to develop an effective data lakehouse architecture:
- Anchor to Business Needs: Assess the business needs and how the lakehouse can address the challenges. Have clarity about use cases and what kinds of insights are necessary, such as BI dashboards, AI/ML models, data for model training and workflow processing, real-time analytics, and so on. Determine the data types and targeted end-users.
- Evaluate the Existing Infrastructure: Critically analyze the current data landscape and identify the limitations of the existing data sources and the ecosystem. This helps in understanding the migration opportunities and also finding the optimal integration junctions.
- Determine the Performance Metrics: Prioritize the success metrics of the data lakehouse implementation strategy. Some of the key metrics to consider are query performance improvements, cost optimization in terms of ETL processing, data clarity, faster time-to-insight, and enhanced user experience.
- Manage Data Smartly: Industry estimates suggest 402.75 million terabytes of data are generated each day. A single high-frequency sensor produces massive amounts of data at an unparalleled pace—transferring all of them to a centralized cloud environment is economically unviable. Instead, review data flows and determine appropriate data residency. For instance, edge processing and regional aggregation are useful in storing information closer to the source, which significantly reduces bandwidth costs. A successful manufacturing cloud platform is designed around where the data resides. Manufacturing cloud data platform architecture must account for data gravity as a core design principle.
- Make Governance a Priority: Ensure that the manufacturing cloud data platform architecture is embedded with governance features and components by design. Embedding governance features such as data lineage, auditing, automated quality checks, and role-based access control helps companies maintain continuous compliance instead of periodic remediation. This is crucial to adhere to regulations such as GDPR and CCPA and data protection frameworks such as Secure Data Storage and Access, Supplier Verification, and the NIST Cybersecurity Framework.
- Fund the Middle Layer: The processing layer is crucial to ensure that the bridge of data flow, from raw data conversion to the final insight-ready output, is seamless. This is the stage where data cleaning, filtration, and normalization occur, which is critical for maintaining quality data. However, most organizations tend to overlook this process.
The shift to a manufacturing data lakehouse architecture provides businesses with a foundation to adopt smart manufacturing at scale. The unified bridge between OT and IT systems allows manufacturers to have an umbrella view of their operations in real-time. This expedites decision-making, maintains precision, enhances quality outcomes, and offers a scalable foundation for AI initiatives and advanced analytics.
However, designing and implementing a modern data architecture for manufacturing requires careful alignment across data engineering, cloud platforms, and operational systems. Challenges such as poor data governance and quality, migration complexities, inefficient optimization, and hidden costs impact implementation effectiveness. This is where working with reliable partners such as Evoke Technologies delivers value.
Data engineering professionals at Evoke assist manufacturing companies in developing the right strategy and expertise needed to realize long-term value from their data investments. Evoke, for instance, streamlined a leading manufacturer’s supply chain workflow by resolving challenges such as data fragmentation and a lack of centralized data accessibility with a Procurement AI Assistant solution. This enabled faster decision-making and improved supplier relationships while ensuring cost optimization. In another use case, Evoke’s OT and IT convergence solutions helped a manufacturer improve business insights and visibility. This, in turn, increased customer engagement by 30%.
Equipped with in-depth knowledge about modernized data architectures and resources, Evoke delivers scalable, flexible, and governance-by-design robust lakehouse solutions tailored for complex industrial environments.
FAQ 1: Why can’t traditional data warehouses handle modern manufacturing data?
Traditional data warehouses are designed for structured business data like finance and sales, not the high-volume, high-velocity, and high-variety data generated by modern manufacturing operations. Factory environments produce massive amounts of data from IoT sensors, MES systems, SCADA platforms, PLC logs, and unstructured maintenance records, which overwhelm legacy warehouse architectures.
A data lakehouse for manufacturing solves this by combining the scalability and flexibility of data lakes with the governance, security, and SQL performance of data warehouses—on a single platform. This architectural shift is accelerating across the industry, with data lakehouse adoption expected to grow from $14.2B in 2025 to $105.9B by 2034, reflecting manufacturers’ need for analytics-ready operational data at scale.
FAQ 2: How does a data lakehouse reduce root cause analysis time in manufacturing?
More than 83% of manufacturers struggle with slow root cause analysis because operational data is fragmented across MES, ERP, CMMS, quality tools, historians, and spreadsheets. Traditional approaches require cross-functional teams to manually extract and reconcile data—often taking days to identify the cause of downtime or yield loss.
A manufacturing data lakehouse unifies OT and IT data—including sensor readings, production orders, quality measurements, and maintenance logs—into a single, queryable source of truth. Engineers can instantly correlate upstream process deviations with downstream failures using one query, reducing root cause analysis from days to minutes and enabling faster corrective actions.
FAQ 3: What is data gravity, and why does it matter for manufacturing cloud architecture?
Data gravity refers to the tendency of large data volumes to become increasingly difficult and expensive to move. In manufacturing, even a single high‑frequency industrial sensor can generate terabytes of data, making it economically impractical to continuously transfer raw data to a centralized cloud environment.
A well‑designed lakehouse cloud architecture for manufacturing accounts for data gravity by leveraging edge computing, regional aggregation, and selective data movement. Processing data closer to where it’s generated significantly reduces bandwidth costs and latency. Ignoring data gravity often leads to unexpected cloud cost overruns, eroding the ROI of manufacturing analytics initiatives.
FAQ 4: Why do predictive maintenance AI pilots fail to scale in manufacturing?
Predictive maintenance pilots often succeed because they operate on clean, limited datasets from a small number of machines. However, when manufacturers attempt to scale these pilots enterprise‑wide, they encounter fragmented data formats, inconsistent asset tagging, vendor‑specific sensor schemas, and siloed historical records.
A data lakehouse architecture for predictive maintenance resolves this by ingesting, standardizing, and contextualizing sensor data from all equipment, plants, and systems into a unified platform. With both real‑time and historical data available together, manufacturers move beyond experimentation and focus on deploying AI models that deliver measurable uptime improvements and ROI.
FAQ 5: What governance practices should manufacturers build into a data lakehouse for compliance?
To meet GDPR, CCPA, and NIST requirements, data governance must be embedded by design, not added later. This includes end‑to‑end data lineage, automated data quality validation, role‑based access control, and continuous auditing across data pipelines.
One of the most critical—and often neglected—elements is the processing and transformation layer, where raw manufacturing data is cleaned, normalized, and enriched. Without strong governance at this stage, even a well‑architected lakehouse delivers unreliable data to dashboards and AI models, increasing compliance risk and undermining trust in analytics across the organization.
Connect with Evoke to learn more.