

Big data is gaining massive popularity in today’s information-driven era. It is considered as one of the hottest IT buzzwords in 2015. It has the potential to solve key business problems by taming large volumes of data and creating meaningful insights. In order to maximize its potential developers are relying on parallel processing architectures, such as Hadoop etc., to process large amounts of data. The future appears very bright for Hadoop, a leading open-source big data framework designed to effectively process large chunks of data stored in distributed clusters. In this blog, we will focus on Hadoop Counters.
Major Components in Hadoop
Hadoop big data framework primarily has two major components:
- Hadoop Distributed File System (HDFS), which deals with the storage.
- Hadoop MapReduce Framework, which deals with data processing.
Hadoop MapReduce Framework
Here’s a quick overview of Hadoop MapReduce framework. The Map function filters data for a given set of conditions, whereas the Reduce function aggregates data from the Map function to generate the final output. The Hadoop MapReduce Framework has certain elements such as Counters, Combiners and Partitioners, which play a key role in improving performance of data processing. Let’s focus on Hadoop Counters.
Dataset Details
The consumer complaints dataset has been used as a sample to demonstrate Hadoop Counters. The dataset consists of diverse consumer complaints, which have been reported across the United States. The dataset consists of complaint number, complaint category/subcategory, complaint description, complaint location, date of complaint and complaint progress. Here’s the screenshot of consumer complaints dataset view, as it appears in HDFS.

User-defined Counters
While processing information/data using MapReduce job, it is a challenge to monitor the progress of parallel threads running across nodes of distributed clusters. Moreover, it is also complicated to distinguish between the data that has been processed and the data which is yet to be processed. The MapReduce Framework offers a provision of user-defined Counters, which can be effectively utilized to monitor the progress of data across nodes of distributed clusters.
Now, let’s use Hadoop Counters to identify the number of complaints pertaining to debt collection, mortgage and other categories in the consumer complaints dataset. The following job code, would help us to accomplish this.
[c]
package com.evoke.bigdata.mr.complaint;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ComplaintCounter extends Configured implements Tool {
@Override
public int run(String[] args) throws Exception {
String input, output;
if(args.length == 2) {
input = args[0];
output = args[1];
} else {
input = "your-input-dir";
output = "your-output-dir";
}
JobConf conf = new JobConf(getConf(), ComplaintCounter.class);
conf.setJobName(this.getClass().getName());
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
conf.setMapperClass(ComplaintCounterMapper.class);
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(IntWritable.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setNumReduceTasks(0);
RunningJob job = JobClient.runJob(conf);
long debt = job.getCounters().findCounter("Debt-Counter", "debt").getValue();
long mortage = job.getCounters().findCounter("Mortgage-Counter", "mortgage").getValue();
long other = job.getCounters().findCounter("Other-Counter", "other").getValue();
System.out.println("Debt = " + debt);
System.out.println("Mortgage = " + mortage);
System.out.println("OTHER = " + other);
return 0;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new ComplaintCounter(), args);
System.exit(exitCode);
}
}
[/c]
The above Java code contains Map-only job and it displays the values of debt collection, mortgage and other occurrences.
Below is the map code, which is used in the above job code. The below map code scans through each line of the dataset and increments debt collection, mortgage and other occurrences.
[c]
package com.evoke.bigdata.mr.complaint;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class ComplaintCounterMapper extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
String[] fields = value.toString().split(",");
if (fields.length > 1) {
String fileName = fields[1].toLowerCase();
if (fileName.equals("debt collection")) {
reporter.getCounter("Debt-Counter", "debt").increment(1);
} else if (fileName.equals("mortgage")) {
reporter.getCounter("Mortgage-Counter", "mortgage").increment(1);
} else {
reporter.getCounter("Other-Counter", "other").increment(1);
}
output.collect(new Text(fileName), new IntWritable(1));
}
}
}
[/c]
Here’s the output, when the above map code is executed:

Hadoop offers Job Tracker, an UI tool to determine the status and statistics of all jobs. Using the job tracker UI, developers can view the Counters that have been created (refer the below screenshot for more clarity).
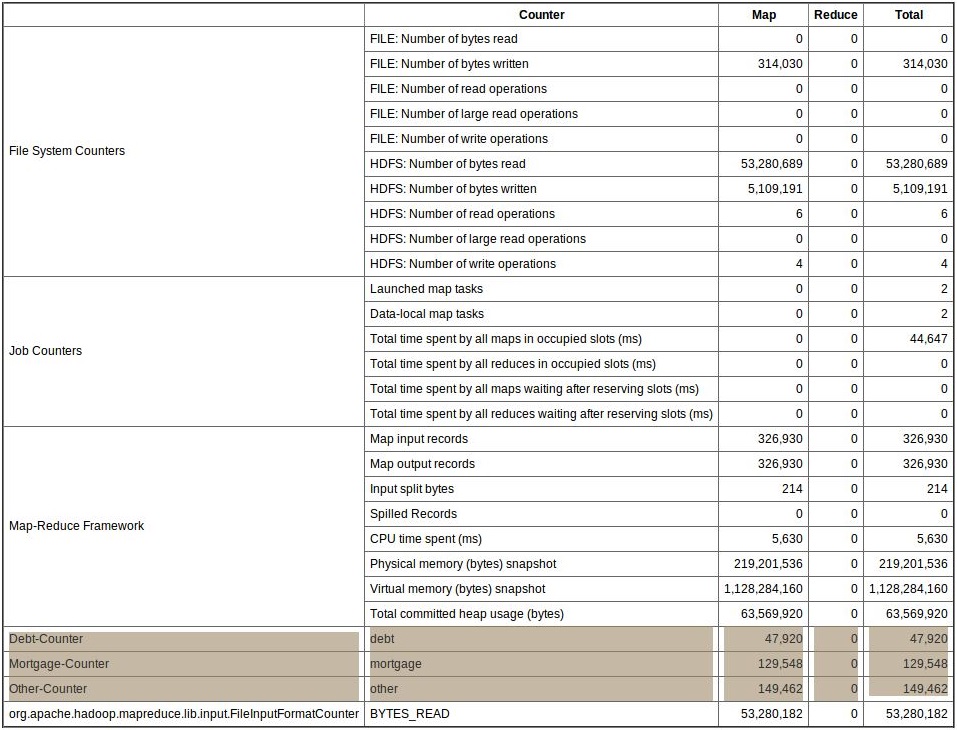
Conclusion
Hadoop is considered as one of the best parallel processing architectures around, it offers some really amazing features. Counter is one such feature in Hadoop that allows developers to track the status of data that has been processed. Additionally, it also helps developers identify junk data and mark it for identification. Hope this post helped developers gain some knowledge on Hadoop Counters, in my next post, I would be talking about Hadoop Combiners.





2 Comments
Hi
As per the code its given String[] fields = value.toString().split(“,”); and comparing the value using fileName.equals(“debt collection”)) , but in sample data which is attached in the blog don’t have field value like “debt collection”. Could you please let me know is my understanding wrong or the sample code is working with different set of data input file.
Thanks
can i get this sample consumer file ?