

The most difficult challenge for enterprises today is getting the text/content from images, boards, scanned images or scanned PDFs. Businesses are spending a significant amount to copy required content/text from images to the database through visual inspection and manual typing process. Companies consider some major factors such as:
- Optimize the budget/cost
- Reduce manual efforts and manual errors.
- Minimize the processing time
Evoke worked on accounting automation for a global leader in the pharma/chemical industry to drastically reduce manual efforts, manual errors, processing time, and budget costs. As part of accounting automation, a solution should read all types of invoices as part of the business (buying the raw chemicals) and populate the results to SQL DB.
Objective
The objective of phase 1 is to prepare an automated solution that can extract all the scanned or system-generated invoices tabular data such as HSN, ITEM, UOM, Quantity, Packs, Rate, Value, etc., irrespective of invoice formats, attributes, and naming conventions. Though not the entire invoice data, this blog explains how tabular data from an invoice can be extracted using different tools.
The major challenges in data extraction from invoices are Optical Character Recognition (OCR) as this depends on:
- The scanning properties
- The invoice preparation at the source
Since both are largely out-of-scope factors for a business, several image preprocessing steps before OCR and post processing steps after OCR are being applied such that the solution gets generalized and accurate.
Tools used are Open CV for image preprocessing, Yolov5 to detect the position of tabular data, Adobe Acrobat OCR to extract text from the table, and python to maintain the generalized format of the invoices.
Pipeline:
Step 1: Convert PDFs to images.
Step 2: Tabular Data Detection using YOLOv5 & Resnet50:
- Using YOLOv5, detect the tabular data, crop the image, and convert it to PDF
- Using Resnet50, detect the tabular data, crop the image, and convert it to PDF
- Compare YOLOv5 accuracy with Resnet50 accuracy
- Compare Original image inputs with YOLOv5 results and Resnet50 results
Step 3: Apply necessary image preprocessing steps.
Step 4: Using Adobe Acrobat OCR, extract the excel format of the cropped converted PDF.
Step 5: Using python code, remove the noise from the extracted excel file and maintain the general structure of the output.
Step 1: Convert PDFs to images.
Using pdf2image. Convert from the path to generate and save the invoice PDF to images.
Step 2: Tabular Data Detection using YOLOv5 & Resnet50:
- YOLOv5 Model Development:
You Only Look Once (YOLO) is the popularly used object detection tool in an image. It has three layers – Densenet which extracts features from images, PaNET to fuse all the extracted features and the YOLO layer which gives the output.
All 372 PDFs are converted to images. Further, these images were labeled using the labelImg tool. Out of 372 files, 276 were taken as train data and 96 as val. The Yolov5 trained model gave an accuracy of 0.995 meaning, the model can detect the table in the invoice correctly 99.5 times out of 100. To know more about how Yolov5 detects the required object in an image, check out our blog “YOLO Modeling for “Checkboxes” Detection/Classification”.
2. Resnet50 Model Development:
Resnet50 is a modification of the Resnet model which is also used for image detection, classification, and prediction. It has a total of 48 convolutional neural networks with 1 max pooling and 1 average pooling layer. The input image is passed through a series of convolutional neural networks to extract features from the images. It is in five stages and finally all these networks are connected to produce an output.

The following steps were taken to predict the table in invoices using Resnet50:
Git clone keras retinanet from git. Resnet50 backbone and other configurations are available in ‘keras_retinanet\models’ of the cloned folder.
All the 372 images converted in Step 1 were labeled using PascalVOC selection in labelImg tool. Presented with below out sample, considering the data privacy.
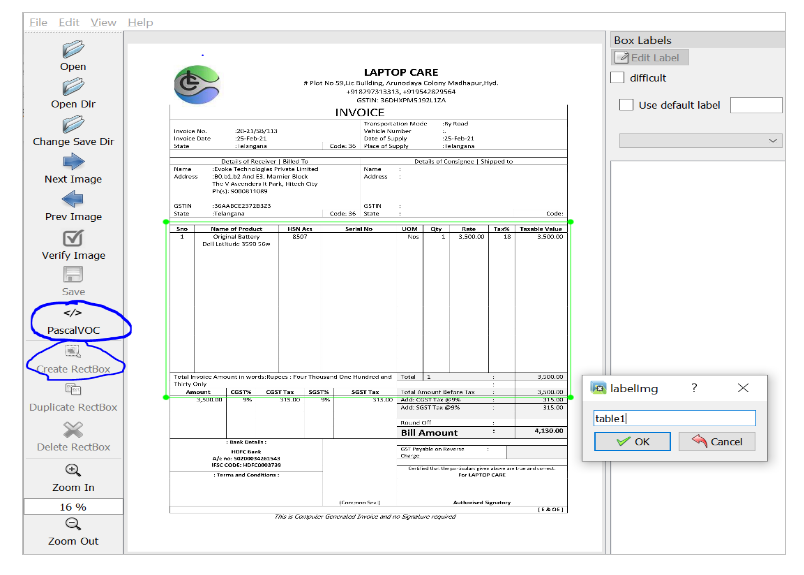
Created below folders:
‘images’ – moved all the images to this folder
‘annotations’ – moved all the annotations generated using labelImg to this folder
‘snapshots’ – kept some pretrained .h5 file in this folder (‘resnet50_coco_best_v2.0.1.h5)
Updated ‘object_detection_retinanet_config.py’ for any changes in the paths, train test compositions.
Ran ‘build_dataset.py’ to create ‘train.csv’, ‘test.csv’,’classes.csv’ in the chosen folder in config file above. Preferred to choose the root folder ‘keras-retinanet’.
Out of 372 files, 276 were taken as train data and 96 as val/test data.
Ran ‘setup.py build_ext –inplace’ to update c++ build tools dependent compute_overlap python file in utils.
Trained the model using the ‘train.py’ in ‘keras_retinanet/bin’ by specifying epochs, steps, weights, paths, etc.
Retrained the model using weights of the trained model, for higher accuracy (such as loss, mAP, precision, recall). Weights of the trained model are stored in ‘model1.h5’.
Created inferential model ‘invoice.h5’ using finalized trained model ‘model1.h5’. Further, used this inferential model ‘inovice.h5’ to generate the predictions and compare.
- Evaluation of YOLOv5 & Resnet50:
Precision, recall, mAP of YOLOv5 is higher than Resnet50 for Train, test, and Outsample formats. Additionally, box/obj loss of YOLOv5 is lower than resnet50. Thus, YOLOv5 has been finalized to push into deployment.
Additionally, Resnet50 is sometimes dependent on C++ build tools, java, etc., which causes difficulty while deploying in different environments.

- Input and Output Comparison:
The images below show the table detected manually (using labelImg) and the table detected using YOLOv5 and Resnet50. It is seen that different tables in the forms are detected at different probabilities. The one with the highest probability is the required table. Yolo model has detected that table with 0.94 probability whereas Resnet50 has detected the table with 0.85 probability.


Step 3: Image preprocessing steps
OCR may fail to extract some of the text, grid, and formats across. This is due to a large number of combinations for scanners, image formats, and factors. Thus, conditional image preprocessing steps were added before sending the above images to OCR. Below are some of the preprocessing steps applied conditionally based on the type of image format detected.
In a nutshell, predicting the scores/values of Bilateral filtering, Adaptive thresholding, Gaussian blur, Median blur, noise, brightness, folds, tilt, alignments, and rotations. Then, predicting optimum level configurations and filters that can be applied based on image quality predictions. Below are the details:
- Change the color of the image to black and white.
- Eliminate any brightness issues and get the full image to one brightness level.
- Improve pixel density which helps in images where there is pixel loss for characters.
- Remove noise present in the document. For example, unwanted dots or noise which affects OCR.
- Fix any rotations and angles that truly required a fix.
Invoice images were first analyzed to determine which image processing technique to apply. Based on the image, its parameters were applied. All these were determined using conditional statements and for loops.
Step 4: Optical Character Recognition (OCR)
OCR techniques convert human written text to machine understandable language by converting two-dimensional images containing texts to numbers. OCR technologies involve deep learning and computer vision modules to extract text features and neural networks to predict the output.

Images after applying preprocessing steps were converted to PDFs to extract texts. Among the many OCRs available, the following are a few that have been tried and tested to extract data from image tables:
- tesseract, b. easy ocr, c. swift ocr, d. doctr , e. paddle ocr, f. Adobe OCR and g. Foxit OCR
Tesseract OCR is finalized considering tesseract OCR is freeware and resulted in 82% document level accuracy (93% field level accuracy) during both Train and Test results.
However, the client requested greater accuracy along with complete automation (without manual intervention) as it was related to accounting. Thus, Adobe OCR is verified as an additional option to get higher accuracy (91% document-level accuracy and 98% field-level accuracy).
Tesseract OCR is a freeware and worked well to extract the data. However, Tesseract OCR cannot get the tabular grids. Thus, developed additional image preprocessing steps with the procedure below:
- Detect the grids.
- Bounding box and split/crop the image based on detected column-wise grids.
- Send cropped images to Tesseract OCR and append them to create a data frame.
However, the above methodology requires the use of hardcoding coordinates that would be maintained separately for each vendor in the vendor’s list corpus until the process gets stabilized. Since the client expected higher accuracy, we tried Adobe Acrobat OCR.
As the entire actions need to happen in a single flow, the actions of adobe acrobat OCR need to be automated. Hence, to accomplish automation, win32 package is used. Pywin32 is a package that establishes connections between COM servers.
Using win32com.client.DispatchEx connection between the system and the application is set up. Then the extension .pdf of the file is replaced with .xlsx, meaning the PDF file is converted to excel output.
Outputs from Adobe Acrobat OCR:
The below image shows the exact table that is cropped from the YOLOv5 outcome image that is required for further steps to extract data.


Final Pipeline Step (Step 5):
In the above excel format, there are few noises that can be removed by hard coding. For example, the column ‘Serial No’ is empty and does not reduce any value even if it is removed. Further, we succeeded in maintaining constant headers for each of the documents. This was done by pre-defining each column header and comparing it with the document’s header. For example, headers like ‘HSN’, ‘HSN Acs’, ‘HSN/SAC’ were all termed as only ‘HSN’ in the final output. Similarly, terms like ‘Quantity’, ‘Qty’, were clubbed as ‘Qty’ and headers like ‘Product Description’, ‘Description’, ‘Name’, ‘Product’ were termed as ‘Name of the product’.
The goal of renaming the headers is to ease the addition and manipulation of data in the SQL Database.
Therefore, after removing the noises excel would look like the below image.

Conclusion
As stated in the blog, the major challenges faced while extracting data from invoices were Optical Character Recognition and detecting the location of tabular data in the invoice. These challenges were overcome by YOLOv5 and Adobe acrobat OCR.
Overall, automating the invoicing process minimizes human efforts and error with minimal manual intervention (due to the criticality of accounting business and the sensitivity of accounting numbers). Thus, HSN, QTY, ITEM, Value, rate, UOM, etc., are being extracted and sent to the database for any invoice format and invoice vendor with different grids and notations with this invoice digitization mechanism.

Author
 |
Chennakesh Saka is working as a Data Science Manager with Evoke Technologies. He holds 11 years of experience in Statistical Models, Machine Learning, Deep Learning, and Text based modelling. He is a technology enthusiast who has served diverse industries including Banking, Retails, Irrigation, and Pharma. | |
 |
Tejaswini Kumaravelu is a Trainee Data Scientist at Evoke Technologies. She holds strong technical knowledge and hands on experience in Machine Learning and Deep Learning Model developments. In her spare time, she tutors orphans, and writes technical blogs and research papers. |




